无意间,看见阿里云提供了针对 Qwen3-0.6B 的蒸馏教程,本文章本质上是跟着阿里云提供的教程学习微调过程,官方教程地址。
借用下阿里云教程的介绍:
大参数模型效果好,但成本高、响应慢。为了在保障效果的同时提升推理速度、降低成本,可首先借助大参数模型完成目标任务的数据生成,并使用这些数据微调小参数模型,使其在特定任务中达到接近大参数模型的表现,这一过程也被称为模型蒸馏。
本方案将以从一句话中提取结构化信息(如收件人、地址、电话)为例,演示如何通过模型蒸馏,让 Qwen3-0.6B 模型在此任务上达到大参数模型的表现。
方案信息
教师模型: GLM4.7
样本信息: 由 GLM4.7 生成约1500+条虚拟数据
微调框架: ms-swift
模型推理: vllm
效果

改动部分
- 新增了
postal_code、remark字段,但postal_code在样本训练时没有特地添加,而是在 system 提示词内加的,所以不一定准确,最主要的还是“从地址推邮编”本质是 地理编码/检索问题,仅靠 0.6B 蒸馏感觉还不如由应用层处理。 - 我重新试用GLM4.7生成了一批 2K 训练样本,没有使用阿里云提供的,主要目的是想提取备注。
样本重新生成
- 包含功能区/开发区/高新区/未来科技城/管委会等
- 包含自治区/自治州/盟/旗等多级行政
- 包含英文/拼音混排行政区(extracted 中要映射为中文规范名称)
- 包含括号备注/路线提示/near地铁口/(原xxx)/收件要求/门禁暗号/时间要求
- 电话号码带空格、全角破折号、+86、分机/转接/ext(phone 规范化且保留转接信息)
- 只有城市,没有省份的地址
- 只有某个区,但没有城市、省份的地址
教程
注意:为了方便起见,建议直接使用阿里云教程内的使用环境(老鸟略过),可领取试用点后可以使用9个小时的环境,主要是已经安装好了 CUDA 等驱动,显卡是A10,内存也给得挺大的。
下载训练数据
| |
安装依赖
- ms-swift 魔搭社区提供的训练框架,支持模型的下载、微调和权重合并,极大简化了微调流程。
- vllm 用于部署微调后的模型,支持高性能推理服务,不仅方便验证微调效果,还可用于生成 API,供业务方直接调用。
| |
ps: 建议分开安装,不然会卡很久。
| |
模型微调
| |
微调的核心代码为:
| |
会自动下载 Qwen3-0.6B,我本地用的3080 12G跑的,大概在10分钟的样子。
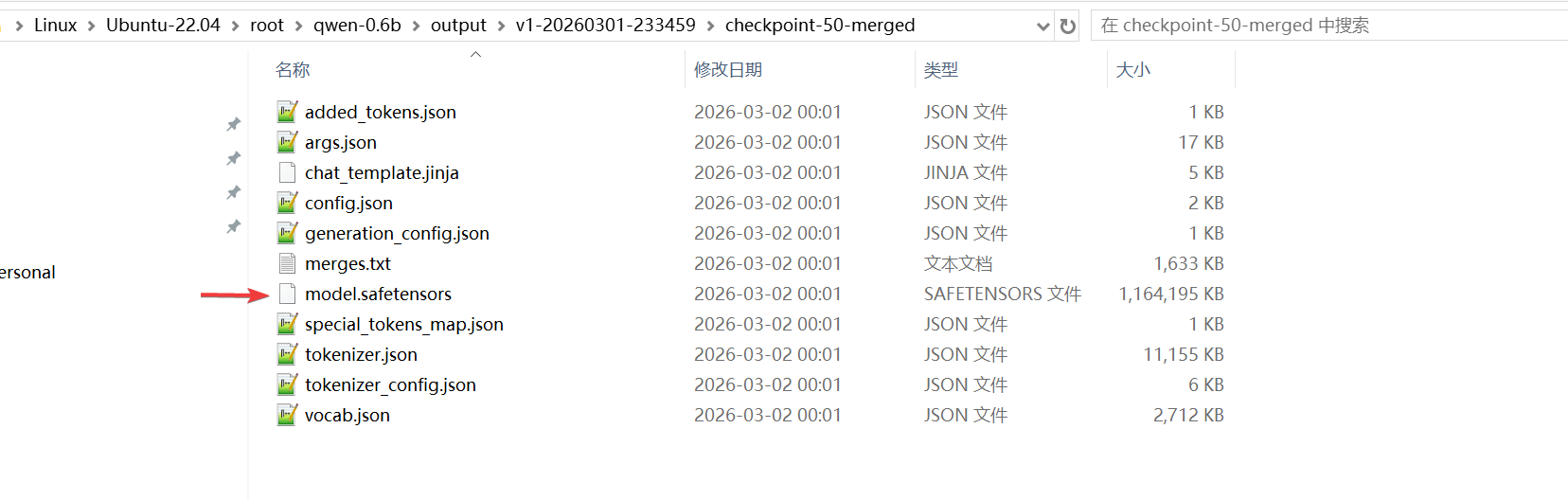
根据脚本内容,训练完成后,会合并LoRA权重,生成合并后模型在output/v0-xxx-xxx/checkpoint-50-merged目录下。
教程内容:
在output/v0-xxx-xxx路径下有 images 文件夹,打开 train_loss.png(反映训练集损失) 与 eval_loss.png(反映验证集损失),根据损失值的变化趋势初步判断当前模型的训练效果:
在结束训练前 train_loss 与 eval_loss 仍有下降趋势(欠拟合) 可以增加 num_train_epochs(训练轮次,与训练深度正相关) 参数,或适当增大 lora_rank(低秩矩阵的秩,秩越大,模型能表达更复杂的任务,但更容易过度训练)的值后再进行训练,加大模型的对训练数据的拟合程度;
在结束训练前 train_loss 持续下降,eval_loss 开始变大(过拟合) 可以减少 num_train_epochs 参数,或适当减小lora_rank的值后再进行训练,防止模型过度训练;
在结束训练前 train_loss 与 eval_loss 均处于平稳状态(良好拟合) 模型处于该状态时,您可以进行后续步骤。本方案的 train_loss 与 eval_loss 变化如下表所示:
验证微调后模型效果(可选)
| |
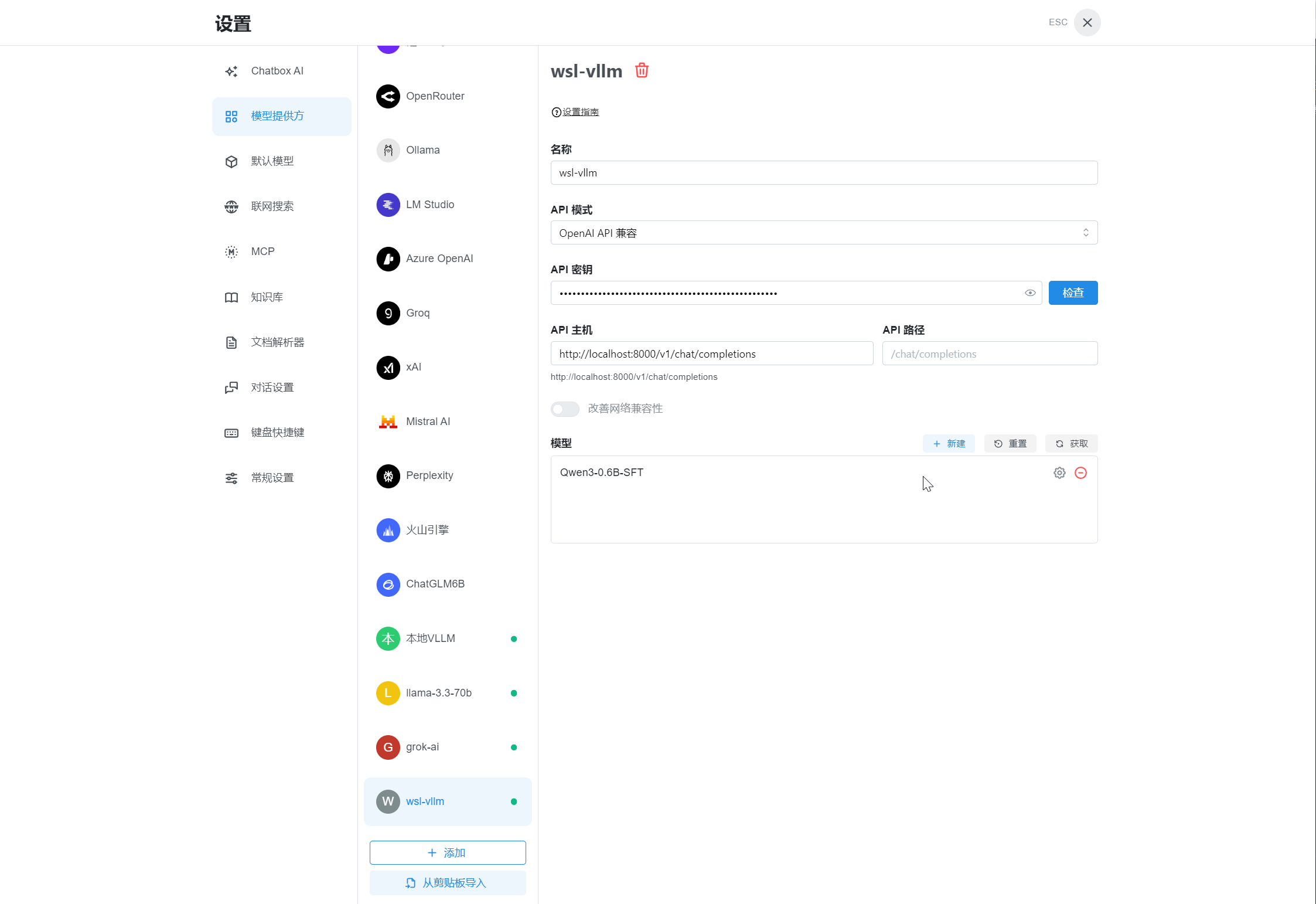
部署为 API 服务
| |
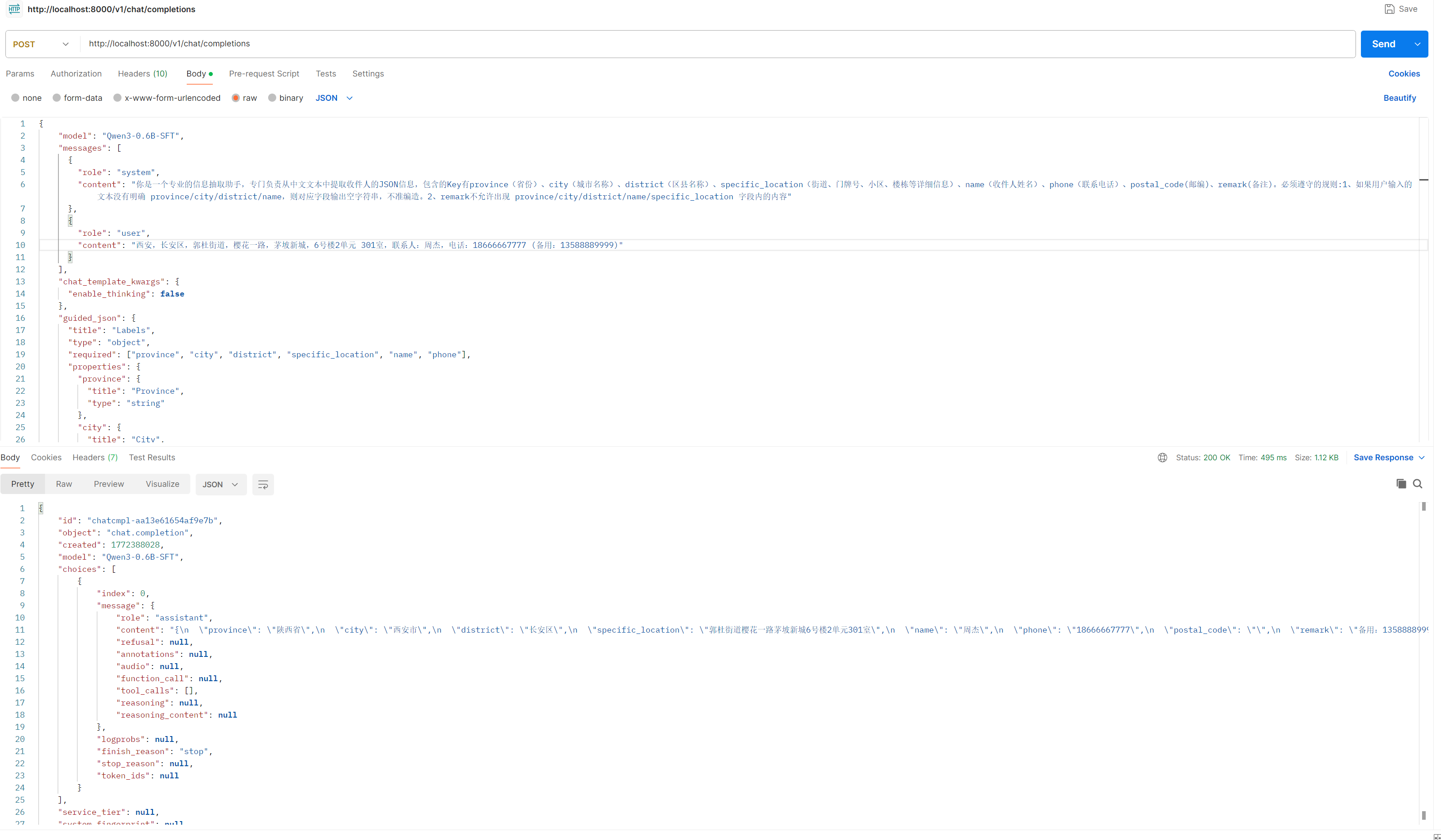
调用方式
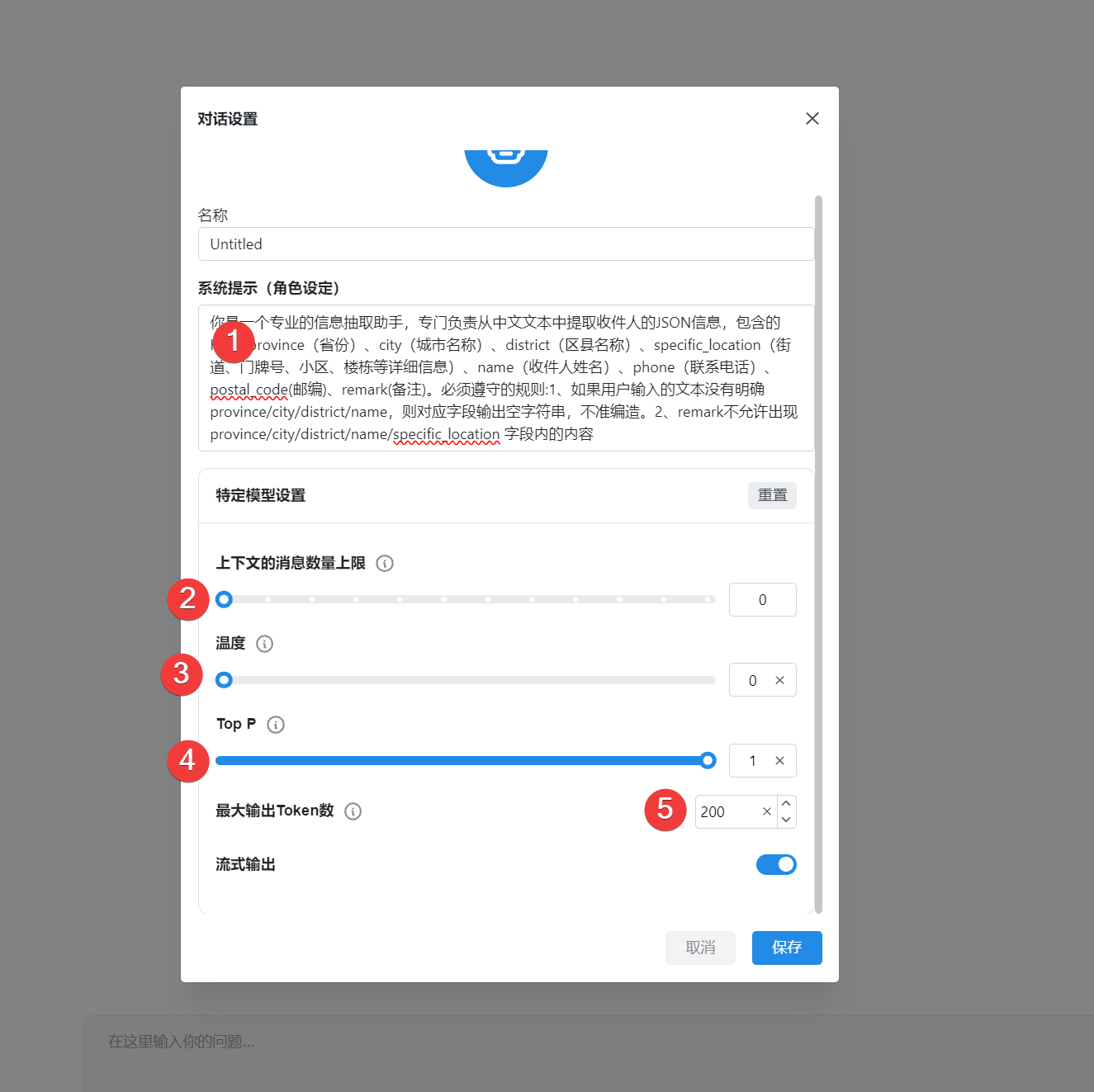
经过我测试,温度设置为 0 ,TOP P设置为 1 好一点。
1、curl
- Authorization需要输入Token
| |
2、Chatbox客户端
添加模型提供方
新会话
总结
对于识别效果,个人感官如果总分给10分,我给8分,可能是0.6B参数量比较小,或者是训练样本的问题,对于 行政冲突、功能区映射与定位、复杂纠错与翻译,处理还是不行,而且还是建立在我重新使用新样本微调的情况下。
自带的样本微调出来只能给到6分左右。但处理常见的地址还是没有问题的。
其次未做 字段提取准确率、召回率、错误率 量化指标,也未对比原大模型(GLM4.7)的效果。
PS:从目前的学习体验来看,蒸馏的整体流程和深度学习模型训练其实有不少相似之处。基本思路都是基于一批样本数据进行训练,通过不断迭代和微调来优化模型效果,并结合召回率、准确率等指标对模型性能进行评估,然后再根据评估结果继续调整训练策略或模型结构。从实践角度来看,本质上也是一个“数据 → 训练 → 评估 → 调整”的循环过程,只是蒸馏更多是在已有模型能力的基础上进行知识迁移和压缩。
2026-03-04 更新
针对以上行政冲突等问题,我重新利用GLM4.7生成了2.8万条样本数据,其中包含
- 行政区冲突样本
- 缺失补全样本
- 定位,新增了字段 zone (功能区),
- 多地址/冲突
- 非“路号”型地址:村镇组/队/屯/号;市场档口/铺位/摊位;或学校/医院/园区内部楼宇(楼/座/科室/院区等)
- 数字混淆:取件码/门禁码 等
- 多号码/分机
- 英文/拼音片段
- 行政区错别字
- 偏远地区
- 行政区缩写与别称
- 模糊POI与硬门牌
- 路名干扰
不再将 功能区 放入 remark 字段中,单独放入 zone 字段。但最好还是模型后置省市区数据库做校验。
训练参数重新调整为
| |
目前发现不足:
| |
还是需要针对性生成200条样本左右,基于新的模型再次蒸馏进行纠正,这一块后续再做。
优点:
- 对于一般的正常地址已经能做到不出错
- 抗干扰与清洗能力
- 复杂的逻辑拆分,对 zone(功能区/开发区)和 remark(备注)的拆分非常灵动。比如能把“与海德三道交汇处”准确放入备注,把“高新区”和“武侯区”分别归类。
- 行政区划补全与规范,能将“新疆”自动扩写为“新疆维吾尔自治区”。
测试地址(虚拟,有难度的情况)(忽略json格式):
| |
本机微调过程(可忽略)
这里记录一下我自己使用本机训练的过程。
ps: 后续涉及到执行python命令,请自行按照自己的python 环境管理器运行,例如我使用的uv,那么执行python前加一个前缀uv / uv run等。
| |
安装uv
| |
安装完成后,可用以下命令验证安装
| |
创建虚拟环境
| |
默认会在当前目录创建 .venv 虚拟环境。
安装vllm
官方版本 根据自己的CUDA版本来。
| |
更多安装教程,可自行搜索(VLLM 部署的一些细节,关于CUDA对应版本的问题)
安装ms-swift
| |
脚本改动
将sft.sh、deploy.sh 执行的python脚本改为 uv 环境运行。如: sft.sh
| |
deploy.sh
此处我固定了API KEY。
| |